Use Data Discovery search to refine datasets for labeling - Beta 🧪
Once your dataset is created, you will want to add records to projects as tasks. For some projects, this might be the complete dataset. But in most cases you will likely want to select a subset of data based on certain criteria.
If your dataset consists of several thousand unstructured items, then manually sorting, categorizing, and structuring that data can take a significant amount of time and effort. Instead, you can use Label Studio’s AI-powered search capabilities to refine your datasets.
Label studio provides several search mechanisms:
- Natural language searching - Also known as “semantic searching.” Use keywords and phrases to explore your data.
- Similarity searching - Select one or more records and then sort the data based on semantic similarity to your selections.
- Combined searches - Combine similarity searching and natural language searching.
- Filtering - Reduce your dataset to only show records that have a certain threshold of similarity to your searches.
attention
Search results are limited to 16,384 records at a time. All records with the dataset are stored, but the Label Studio interface is limited to returning a smaller subset per search. As you change your search query, you’ll see different sets of records (all with a max of 16,384 at a time).
How searches work
Embeddings
When you sync a dataset, Label Studio generates an embedding for each item (or “record”). An embedding is a way of converting complex, often high-dimensional data (like text or images) into a simpler, lower-dimensional form. Our embeddings are generated using an off-the-shelf CLIP model.
For example, say you have a library of books and you want to catalog and sort them. Now imagine how helpful it would be to have a summary of each book written out on a small card, capturing its most important themes or ideas. These cards represent the books in a more manageable way, just like embeddings represent complex data in a simpler format.
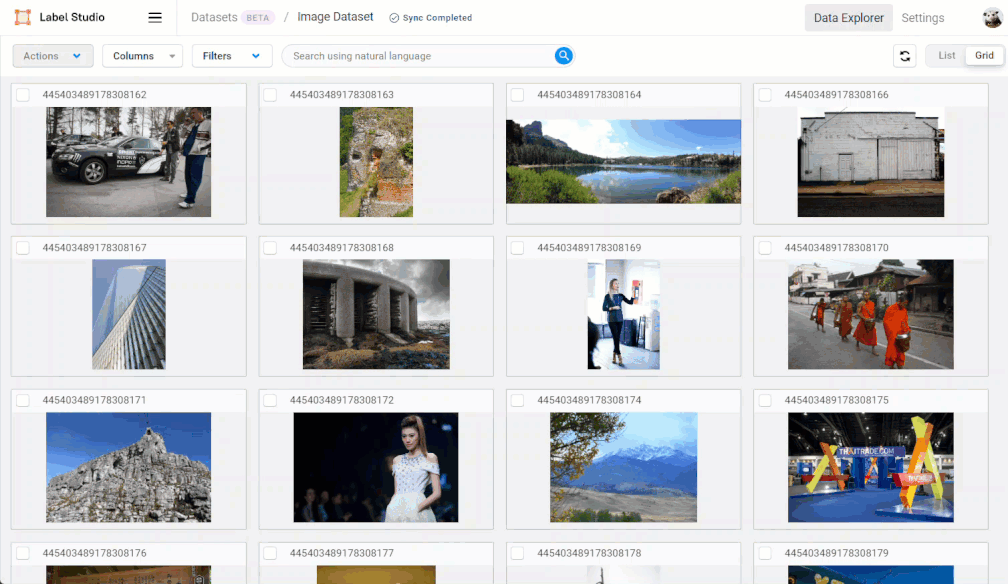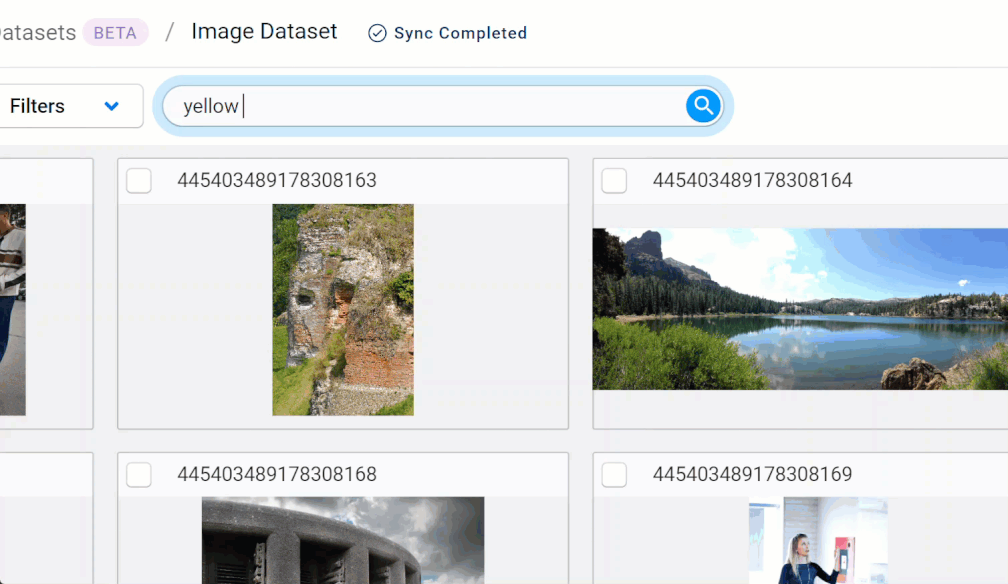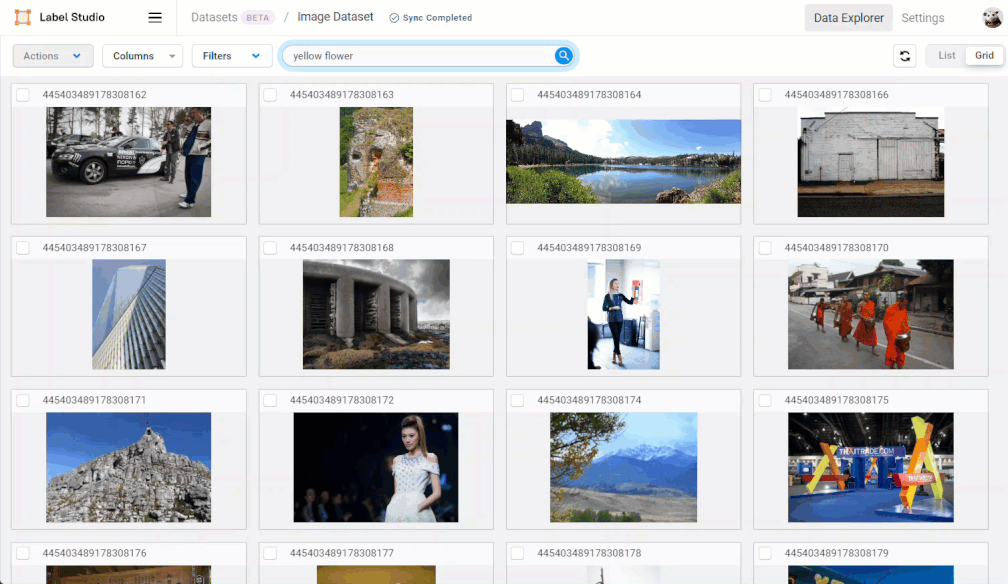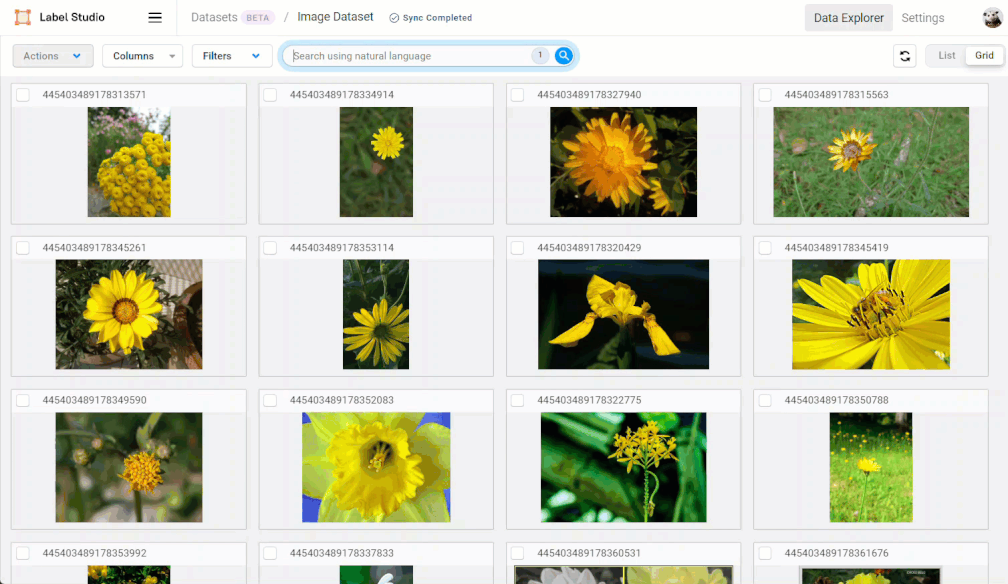
Embeddings also convey meaning in ways that things like keywords and metadata do not. For example, you might want to search your library for “healthy eating.” A traditional search might just look for books with those exact words in the title or text. But an AI-powered semantic search using embeddings would understand the concept of healthy eating and find books related to nutrition, dieting, healthy recipes, and more, even if they don’t use the exact words “healthy eating.”
Reference embeddings
When you perform a search, we generate a single “reference embedding” representing your search query.
If your search consists of one natural language query or one record (in a similarity search), then generating the reference embedding is straightforward.
But when you start performing more complex searches with multiple search terms and records, we need to combine your queries to create the reference embedding.
If you are combining multiple queries in a natural language search, we generate embeddings for each search term and then average them to create a singular reference embedding. Each query is afforded equal weight when calculating the average for the reference embedding. Meaning, for example, that we do not take the order in which you entered your queries into consideration.
Likewise, if you select multiple records when performing a similarity search, we average the embeddings of each record to create the reference embedding.
If you combine similarity searching and natural language search terms, the natural language search reference embedding is created in one operation and the similarity search reference embedding is created in another operation. Then, in a third operation, the two reference embeddings are combined. By doing this, we can calculate a lower weight for the similarity search portion. This is because natural language queries tend to be more accurate descriptions of what you’re trying to find.
Calculating similarity
In its raw form, an embedding is essentially multiple floating points within an array. This means that we can mathematically calculate similarity and assign a numerical similarity score to each record. The similarity score is the distance between those floating points.
First, we take your reference embedding, and then we compare it to the embeddings generated from each record in the dataset. From there we calculate the distance between points within their arrays, and the result is the similarity score.
The closer the similarity score is to 0, the less distance between points, and the more confident we are that the record is a match to your search criteria. The higher the score, the more distance between points, and similarity diminishes.
You can use this principle to filter your datasets by a similarity threshold (see Search results and refining by similarity below).
Natural language searching
You are probably already very familiar with natural language searching (also known as “semantic” searching). Natural language search is simply searching with text queries like keywords (e.g. “plants”) or phrases (e.g. “which plants grow the fastest”).
To perform a natural language search, enter your query into the search field provided. You can keep adding search queries to refine your search.
note
Searches are sticky and cumulative. For example, when you execute two searches in a row, both queries are used to calculate similarity. To start over, you must manually clear your previous search.
Similarity searches
To perform a similarity search, select one or more records. From the Actions menu, select Find similar.
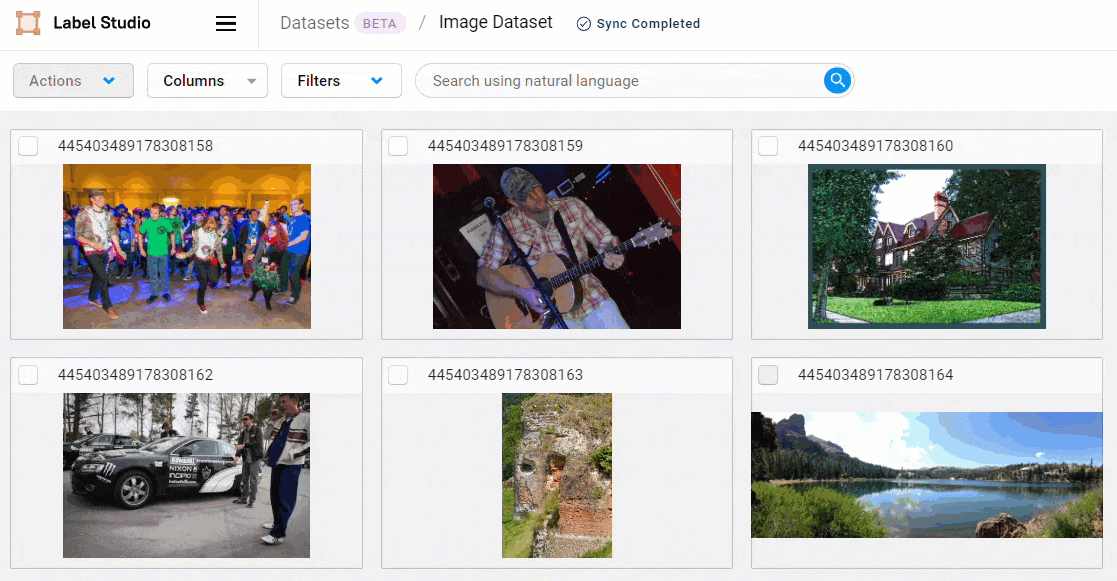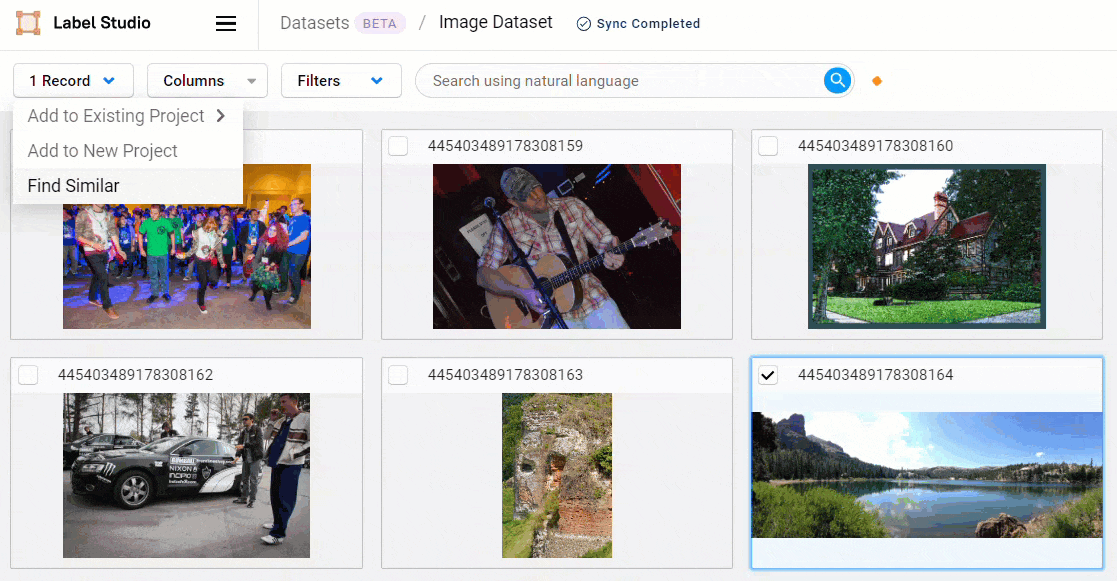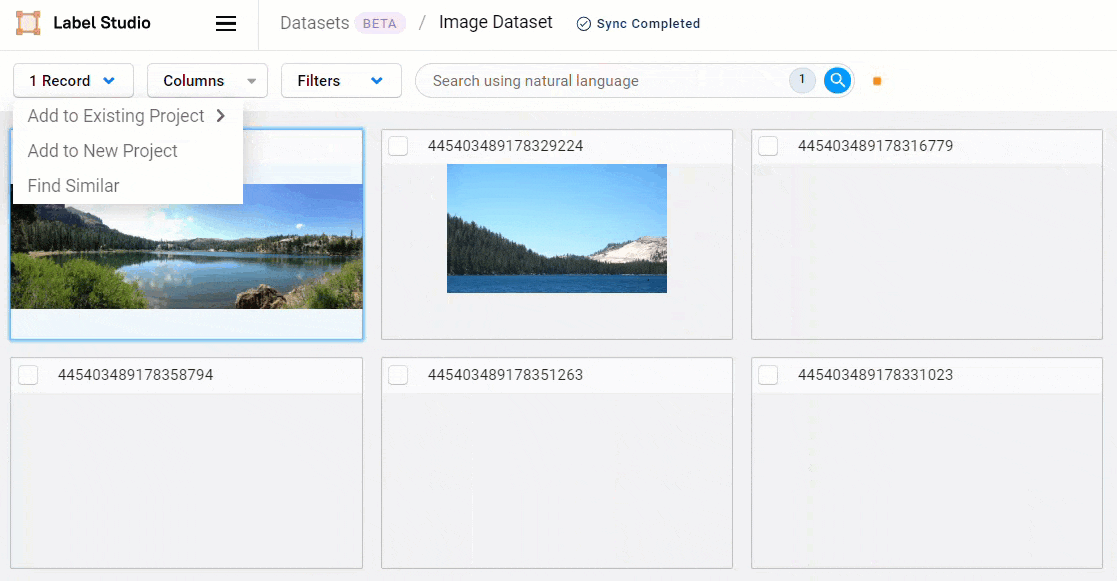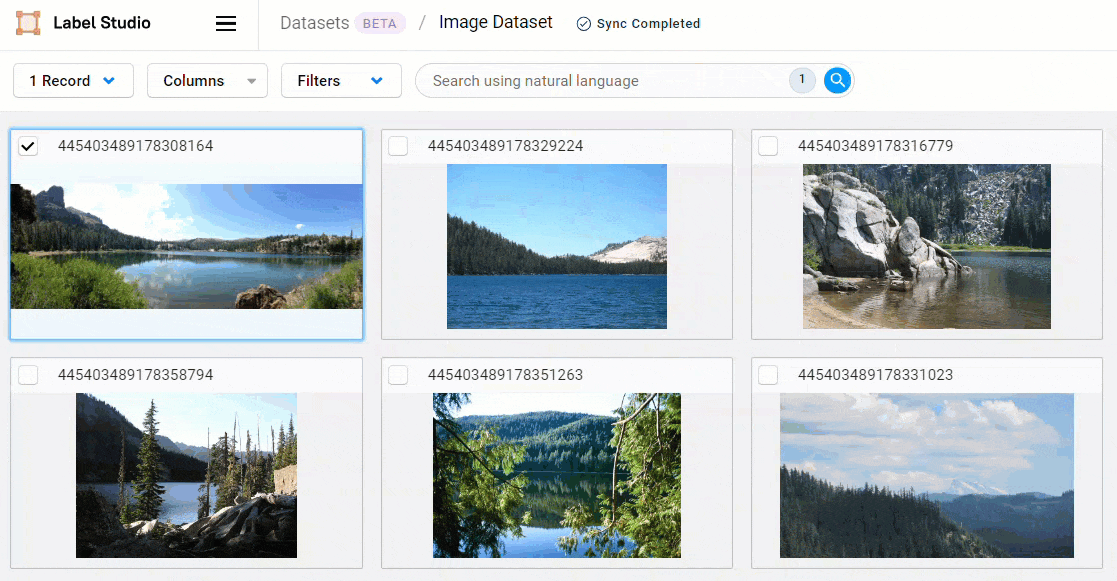
You can continue to refine your similarity search by adding and removing records from the query.
To adjust your search, simply select or deselect records and click Find similar again.
Search results and refining by similarity
It is important to note that when you perform a search against a dataset, you are not applying a filter. The search does not return a subset of “matches.” Instead, it returns your entire dataset sorted by similarity.
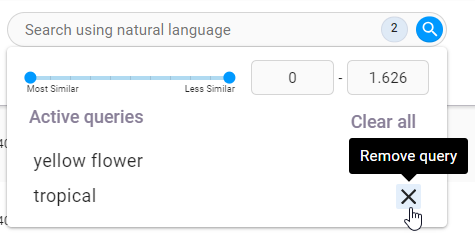
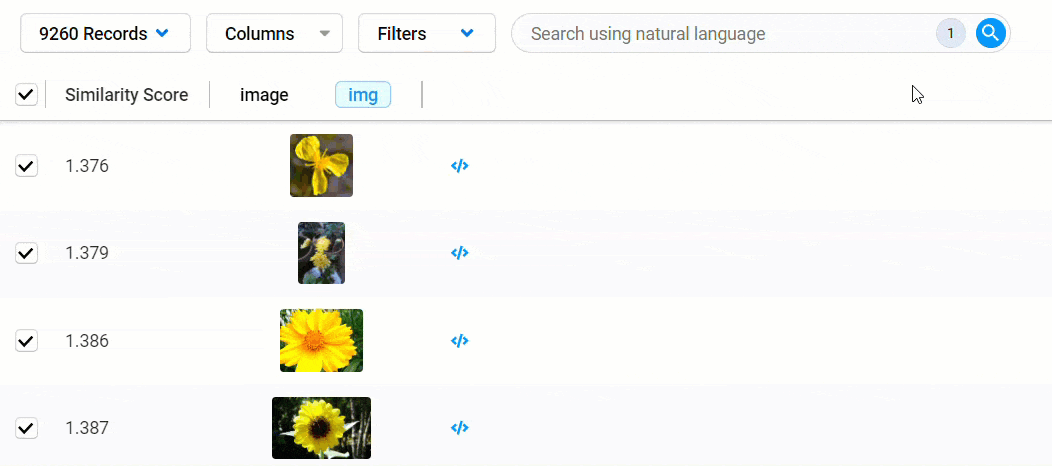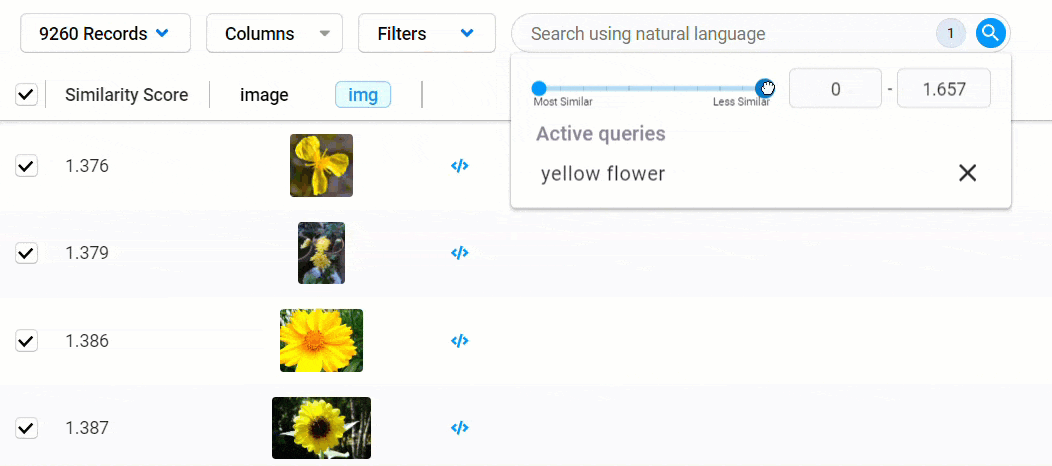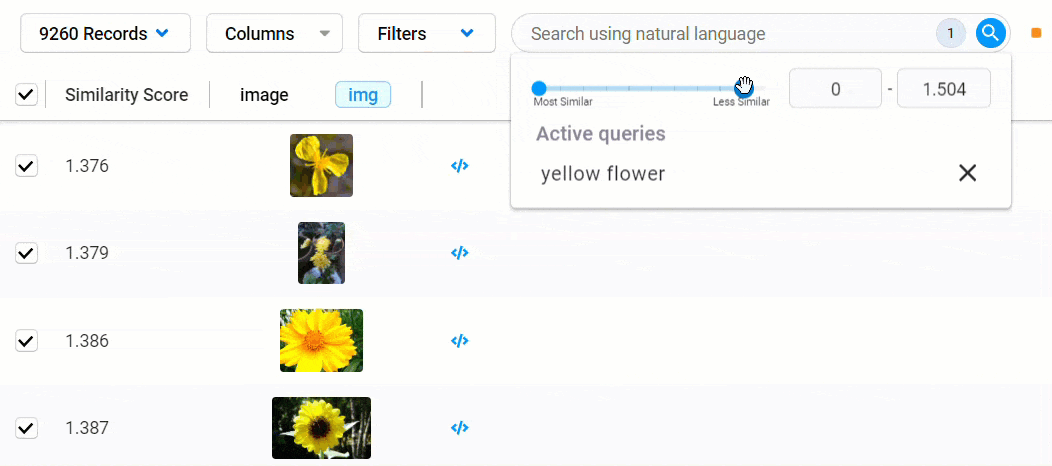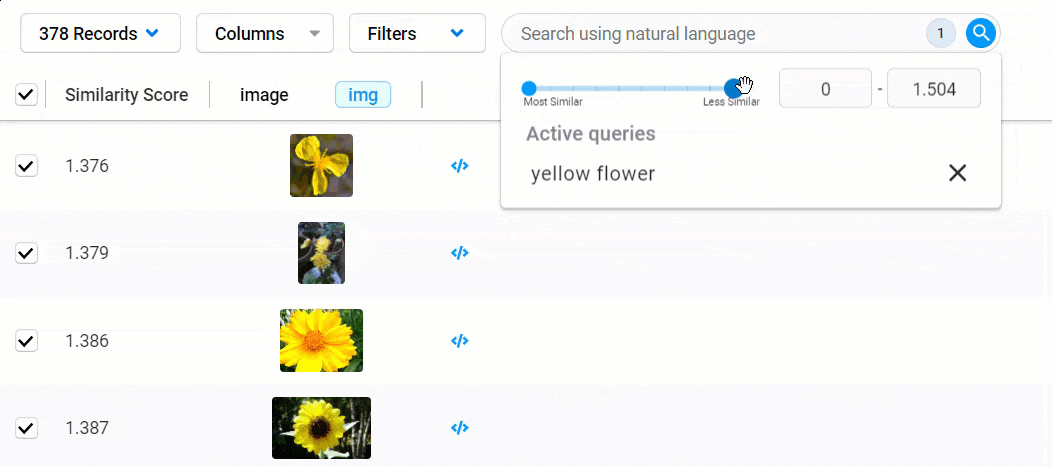
To reduce your dataset to records that meet a certain threshold of similarity, click the search field to view your search criteria and a similarity score filter.
To set the similarity threshold, you can use the slider or enter a value into the field provided.
Create labeling tasks
Once you have refined your dataset, you can create tasks by exporting dataset records to a project.